A basic knowledge of Python (and, optionally, of Jupyter Notebooks) is all that is required to run "in-silico experiments" (simulations) with Life123 !
Ready for a slightly-deeper intro dive? video
text
NOTE: for examples of usage and tutorials, see the Experiments.
The unit tests of the various python functions can also be of help.
For the JavaScript modules, see the Visualization section.
How to get started using these libraries: see our quick start page!
Software REPOSITORY
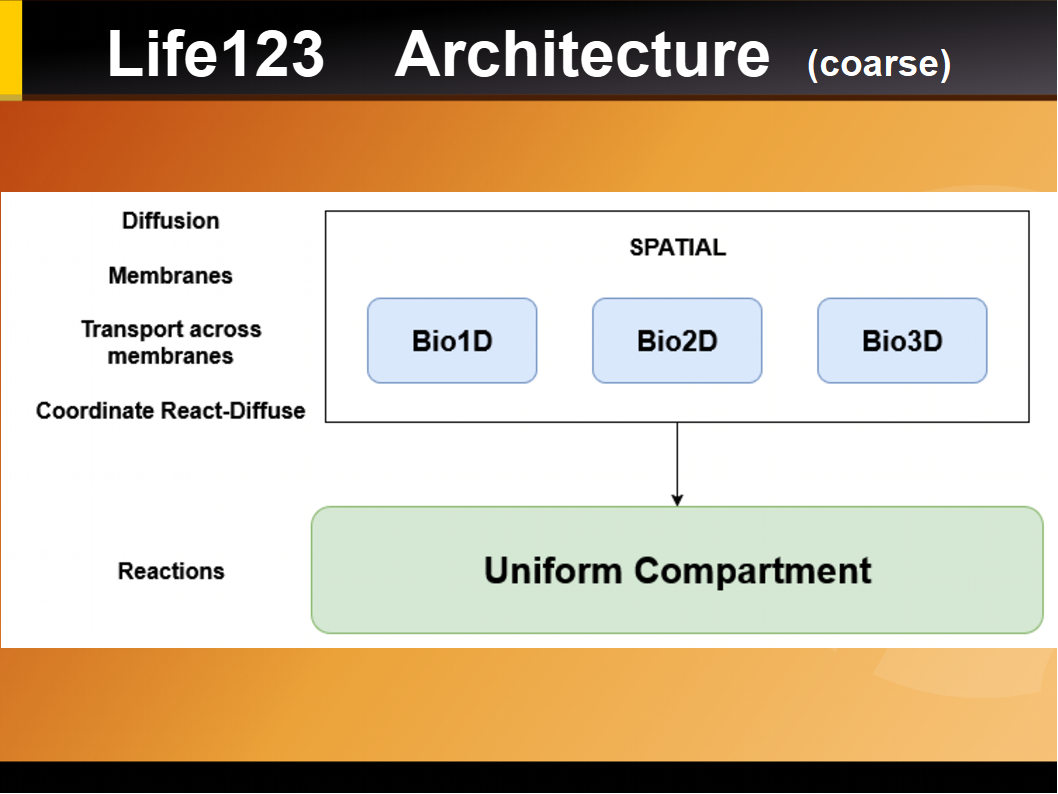
The following libraries (python classes) are being used:
1D simulations of diffusion and reactions, including passive transport across membranes.
2D simulations of diffusion and reactions. Early implementation of membranes.
3D simulations of diffusion and reactions (early implementation)
THIS CLASS HAS BEEN OBSOLETED BY "SpeciesRegistry" and "Species", below. The parent classes "ChemCore" and "Diffusion" have similarly been obsoleted. The other parent class, "Macromolecules" is now separate. OLD Reference Guide
These classes replace the now-obsolete class "ChemData"
"Species" is adata class. "SpeciesRegistry" manages all species, as well as any diffusion data.
The class "Macromolecules" (early implementation) is also hosted in the same file.
USAGE EXAMPLE:
my_species = Species(
id="metK",
categories=["protein", "enzyme"],
molecular_weight=43000,
ec_number="2.5.1.6",
metadata={"compartment": "cytosol"}
)
Assorted, general numerical methods
Generate and manage random networks of reactions that are thermodynamically possible, and biologically plausible.
7 classes:
ReactionCommon, ReactionOneStep,
ReactionUnimolecular, ReactionSynthesis, ReactionDecomposition,
ReactionEnzyme, ReactionGeneric
The objects from those classes are managed by the class ReactionRegistry.
Manage the reaction-specific classes, such as ReactionUnimolecular, ReactionSynthesis, ReactionDecomposition, ReactionGeneric, ReactionEnzyme, etc. (this class was formerly called "Reactions")
2 classes:
1) Static methods about reactions kinetics
2) Methods for managing variable time steps during reactions
Manage the Thermodynamics aspects of reactions:
changes in Gibbs Free Energy, Enthalpy, Entropy - and how
they relate to equilibrium constant, at a given temperature.
This class does NOT get instantiated.
UNITS internally used (same as the DEFAULT units for the function calls):
Temperature: degree K
Energy: kJ <- NOTE the divergence from SI units, for familiarity of convention
Molar energy: kJ/mol
Molar entropy: Joules/(mol·K) <- NOTE : Joules, NOT kJ, for the entropy!
USING ALTERNATE UNITS:
We're *beginning* to phase in the units.py module.
Some - but not yet all - functions now accept arguments such as temp=(25, C)
ENTITIES:
"K" (equilibrium constant - from thermodynamic data)
"delta_H" (change in Enthalpy: Enthalpy of Products - Enthalpy of Reactants)
"delta_S" (change in Entropy)
"delta_G" (change in Gibbs Free Energy)
No correction is made for the temperature dependency of delta_H

from life123 import ThermoDynamics
result = ThermoDynamics.extract_thermodynamic_data(temp=100, delta_H=0.5, delta_S=-3)
# Will return {'K': 0.38205953171118767, 'delta_H': 0.5, 'delta_S': -3, 'delta_G': 0.8}
# Note that temp is in degree Kelvin, delta_H and delta_G are in kJ/mol, while delta_S is in Joules/(mol·K)
Used to simulate the dynamics of reactions (in a single compartment)
For color-related matters
To assist in the use of the plotly library
Facilitate data preparation for graph visualization using the Cytoscape.js library. The development of this library is shared with the sister project BrainAnnex.org
To simplify use of HtmlLog and Vue components from within this project
An HTML logger to file, plus optional plain-text printing to standard output
A "tabular collection" is a Pandas dataframe
built up from a sequence of "snapshots" of data that's in the form of a python dictionary
(representing a list of values and their corresponding names),
such as the state of the system or of parts thereof.
Each data "snapshots" is taken at different times,
or results from varying some parameter.
Each snapshot - incl. its parameter values and optional captions -
will constitute a "row" in a tabular format
MAIN DATA STRUCTURE for "tabular" collections:
A Pandas dataframe
Use this structure if your "snapshots" (data to add to the cumulative collection) are Numpy arrays,
of any dimension - but always retaining that same dimension.
Usually, the snapshots will be dump of the entire system state, or parts thereof, but could be anything.
Typically, each snapshot is taken at a different time (for example, to create a history), but could also
be the result of varying some parameter(s)
DATA STRUCTURE:
A Numpy array of 1 dimension larger than that of the snapshots
EXAMPLE: if the snapshots are the 1-d numpy arrays [1., 2., 3.] and [10., 20., 30.]
then the internal structure will be the matrix
[[1., 2., 3.],
[10., 20., 30.]]
A "Collection" is a list of snapshots of any values that the user wants to preserve,
such as the state of the entire system, or of parts thereof,
either taken at different times,
or resulting from varying some parameter(s)
This class accept data in arbitrary formats
MAIN DATA STRUCTURE:
A list of triplets.
Each triplet is of the form (parameter value, caption, snapshot_data)
1) The "parameter" is typically time, but could be anything.
(a descriptive meaning of this parameter is stored in the object attribute "parameter_name")
2) "snapshot_data" can be anything of interest, typically a clone of some data element.
3) "caption" is just a string with an optional label.
If the "parameter" is time, it's assumed to be in increasing order
EXAMPLE:
[
(0., DATA_STRUCTURE_1, "Initial state"),
(8., DATA_STRUCTURE_2, "State immediately after injection of 2nd reagent")
]
For the management of reaction diagnostic data
For the management of historical data for bin concentrations
For the management of historical reaction-rate data for Uniform Compartments
For the management of historical concentration data for Uniform Compartments